In continuation from my last post – Creating a large dimension,
this post will describe how we obfuscated data in an existing cube.
The premises on which these 2 processes were built, was to mimic the
most voluminous cube for support; then reproduce the myriad of issues
that accompanied this cube (be it in TM1, Cognos BI or Cognos Insight).

 To illustrate, I have built a sample
cube with few dimensions. Time dimension has months from Jan 2014
through Dec 2014. There is Chart of Accounts as well as dimension with
Regions (picked from Planning Sample database). Also there is a
dimension called “aLargeDim” – this is the one with close to half a
million elements in it. For the purpose of demonstration I have created
it with 1,000 elements in it.
To illustrate, I have built a sample
cube with few dimensions. Time dimension has months from Jan 2014
through Dec 2014. There is Chart of Accounts as well as dimension with
Regions (picked from Planning Sample database). Also there is a
dimension called “aLargeDim” – this is the one with close to half a
million elements in it. For the purpose of demonstration I have created
it with 1,000 elements in it.
Turbo Integrator (TI)
process we have consists of code in Prolog, Data and Epilog tabs. The
original process I had, is slightly modified to add dummy data to the
cube. Since I cannot attach files in WordPress, I will explain it with
snippets of code. Please note that I have only shown snippets of code.
It will serve you as a template to build on it.
Parameters

You’d need to specify
the cube name and option 1 (to add dummy data) or 2 (muddle data to
make it unintelligible). The last 2 parameters are required, if you are
adding new data. It controls the volume of data being added (defined
in percent) and on what dimension you’d like to control.
Prolog
Some housekeeping steps like disabling the logging on cube is not shown. Bulk of the code in Prolog is made up of the while loop.- If we are adding data, then we are calculating the number of intersections in the cube (highlighted in maroon color)
- If we are adding data, then pick only percentage of members from the dimension mentioned in the parameter name (highlighted in green color). Say there are 1,000 elements in it and pi_PercentPopulate is 20, then the code will pick every 5th element (100/20 = 5) … there by totaling the number of that dimension elements to 200 (20% of 1000 = 200)
- If we are adding new data, then we need to pick cells in a view that are zero (skip zeroes set = 0)
- If we are making existing data unintelligible, then we need to pick only the non-zero value (skip zeroes set = 1)
vi_CellCount = 1;
vi_AddCount = 0;
i = 1;
vs_DimName = TabDim (vs_CubeName, i);
WHILE (vs_DimName @<> ”);
# Calculate the total cell count. This is required when we need to populate a % of cells
vi_DimSiz = DimSiz (vs_DimName);
vi_ElemCnt = 0;
IF (pi_AddData = 1);
WHILE (vi_DimSiz > 0);
IF (ElLev (vs_DimName, DimNm (vs_DimName, vi_DimSiz)) = 0 );
vi_ElemCnt = vi_ElemCnt + 1;
ENDIF;
vi_DimSiz = vi_DimSiz – 1;
END;
vi_CellCount = vi_CellCount * vi_ElemCnt;
ENDIF;
IF (SubsetExists (vs_DimName, vs_SubName) <> 0 );
SubsetDeleteAllElements (vs_DimName, vs_SubName);
ELSE;
SubsetCreate (vs_DimName, vs_SubName);
ENDIF;
IF (Upper (ps_DimName) @= Upper (vs_DimName) & pi_AddData = 1);
# If the dimension name matches to the prompt value, then pick only % of its elements
# Ex: if pi_PerCentPopulate = 20, then pick 20% of elements from this dimension
vi_DimSiz = DimSiz (vs_DimName);
vi_ModCount = Round (100 \ pi_PercentPopulate);
vi_SubInsPt = 1;
WHILE (vi_DimSiz > 0);
IF (ElLev (vs_DimName, DimNm (vs_DimName, vi_DimSiz)) = 0 & Mod (vi_DimSiz, vi_ModCount) = 0);
SubsetElementInsert (vs_DimName, vs_SubName, DimNm (vs_DimName, vi_DimSiz), vi_SubInsPt);
vi_SubInsPt = vi_SubInsPt + 1;
ENDIF;
vi_DimSiz = vi_DimSiz – 1;
END;
ELSE;
# Otherise use all the elements in the dimension
SubsetIsAllSet (vs_DimName, vs_SubName, 1);
ENDIF;
ViewSubsetAssign(vs_CubeName, vs_ViewName, vs_DimName, vs_SubName);
i = i + 1;
vs_DimName = TabDim (vs_CubeName, i);
END;
vi_NumOfDims = i – 1;
# If we are adding data and ps_DimName is not a valid one, then quit
# Otherwise we will end up processing 100% of intersections
IF (pi_AddData = 1 & vi_SubInsPt <= 1);
ProcessQuit;
ENDIF;
IF (pi_AddData = 1);
# If we are adding data, then we need to conisder the blank cells
ViewExtractSkipZeroesSet (vs_CubeName, vs_ViewName, 0);
ELSEIF (pi_AddData = 2);
# If we are modifying data, then we ned to modify only the non-zero cells
ViewExtractSkipZeroesSet (vs_CubeName, vs_ViewName, 1);
ENDIF;
Data Tab
In the data tab, we
call a random value and then multiply it with the existing data (if
required). The underlined piece feel free to change it whatever you
want.
vi_RandVal = Rand ();
IF (pi_AddData = 1);
# Skip every so often
vi_Populate = IF (vi_RandVal < 0.33333, 0, 1);
IF (vi_Populate = 0 );
ItemSkip;
ENDIF;
IF (vi_AddCount > (pi_PercentPopulate * vi_CellCount \ 100));
ProcessBreak;
ENDIF;
ENDIF;
vi_Sec = StringToNumber (TimSt (Now (), ‘\s’) );
vi_NewVal = (NValue + (100 * vi_Sec) ) * 0.75 * vi_RandVal ;
vi_AddCount = vi_AddCount + 1;
IF (vi_NumOfDims = 2);
CellIncrementN (vi_NewVal, ps_CubeName, Dim_001, Dim_002);
ELSEIF (vi_NumOfDims = 3);
CellIncrementN (vi_NewVal, ps_CubeName, Dim_001, Dim_002, Dim_003);
ELSEIF (vi_NumOfDims = 4);
CellIncrementN (vi_NewVal, ps_CubeName, Dim_001, Dim_002, Dim_003, Dim_004);
ELSEIF (vi_NumOfDims = 5);
CellIncrementN (vi_NewVal, ps_CubeName, Dim_001, Dim_002, Dim_003, Dim_004, Dim_005);
… R E P E A T T H E B L O C K F O R A S M A N Y D I M E N S I O N S Y O U H A V E
Epilog tab has not much code in it, except to turn the logging on the cube, back to initial value.
Demonstration

Ok, not literally … but for those, who insist on seeing accurate numbers (to the decimal) it may lead to confusion :)

I have entered some predefined values in ‘Sales’ account for Jan 2014. This is what the data looks like. Nice, round numbers are present. We will run the code with option 2 for pi_AddData parameter.
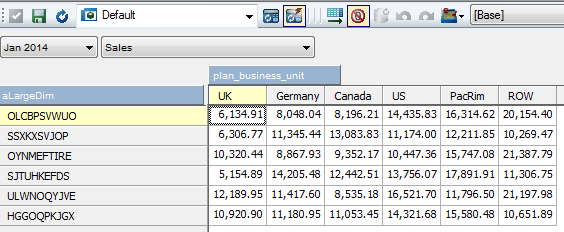
This
is the output after running the process. Process runs fairly fast, as
we have to work with <100 rows. As you can see the numbers are
distorted.
Let’s
clear the data in the cube and re-run the process with pi_AddData = 1
and populate about 5% of cells. The output will look something like
this – shown for couple of accounts for Jan 2014. Data however is
spread across all the months and accounts.

References:
- Dilbert cartoon is from Scott Adams’ site – http://dilbert.com/strip/2008-05-08
- Refer to my blog post for creating a 127 Dim cube, which is used as data source for the TI process
No comments:
Post a Comment